]]>
https://jysperm.me/2023/08/leaving-leancloud/2023-08-11T17:00:00.000Z
从我 2015 年 加入 LeanCloud 已经 7 年多了,这是我人生中非常重要的一段时间,第一次独居、和蛋黄恋爱结婚、辗转三个城市、有了自己的积蓄、新冠疫情]]>
离开 LeanCloud2023-12-20T09:06:11.000Z王子亭jysperm@gmail.com
在最近几年,我发现自己渐渐买齐了差不多所有的 Apple 设备,我使用 MacBook Pro 在写这篇文章、工作时使用 Mac mini、手机是 iPhone、手上戴着 Apple Watch、使用 AirPods 听播客、在床上用 iPad mini 看视频,蛋黄同样也有自己的 iPhone、MacBook Air、iPad Pro 和 AirPods,我们家里还有一个 HomePod mini。
数据安全与隐私
我选择 Apple 的第一个理由是数据安全,iPhone 和 Mac 都是在业界率先普及全盘加密,并在近些年开始使用硬件安全隔区(Secure Enclave)强制加密的。就像 Apple 的很多功能一样,因为其对软硬件的垂直整合能力,Apple 可以在其所有品类的设备上,提供水平相当的数据安全保证。Apple 也在其在线服务中尽可能使用端到端加密,iMessage、健康、家庭等功能此前已经是端到端加密,2023 年起包括备份、文件、照片、备忘录、iMessage 聊天记录在内的几乎所有 iCloud 服务也都支持了端到端加密(Advanced Data Protection)。
在隐私保护方面,Apple 也是最特别的一家厂商 —— Apple 八成以上的收入来自于消费级硬件的销售,这也是 Apple 唯一的主营业务。这意味着 Apple 的商业模式决定了,相比于主要收入来自于广告和增值服务的互联网公司、相比于消费者业务仅占收入一小部分的软件公司,Apple 更有可能与消费者站在一起。
因此 Apple 的设备上你几乎见不到广告,Apple 也不会帮助第三方收集行为数据和投放广告,在互联网公司千方百计地希望你将数据上传到云端时,Apple 则是唯一坚持设备端机器学习的厂商 —— 将(明文的)数据留在设备端,使用设备端的机器学习芯片来提供 AI 能力。
我知道在一些人看来 Apple 不配于谈隐私,如果注重隐私的话应该使用能够自己掌控所有数据的开源方案。但我仍希望选择一家商业公司来获得更多便利和保证,Apple 则是其中最好的一个选择。
软件生态
对于大部分普通用户来说,Apple 最吸引人的是它的第一方软件生态,这些软件和系统、硬件有着深度的整合,有着非常不错的跨设备使用体验,也贯彻了前面提到的对数据安全和隐私的保护,以及 Apple 的对美学、工具和创造、社会责任和家庭等方面的追求。
这种贯穿所有设备的一致体验在所有第一方应用上都有体现,比如我平时每天都会用到的 Safari、备忘录、邮件、地图、播客等应用,虽然相比于更专业的第三方应用,这些系统内建应用的功能都比较有限,但它们共同保证了 Apple 设备的体验下限。曾经摄像头对我来说也是「扫个二维码而已」,但正是因为 Apple 提供了这样的照片拍摄、整理、处理的体验,才让我在最近几年慢慢喜欢上了摄影。
Apple 对于第三方应用有着非常强的控制,或者换一个角度来说是 Apple 非常善于搭建一个生态让第三方应用能够接入其中,权衡哪些部分应该由系统控制,哪些应该由应用发挥。例如 CloudKit、MapKit、HomeKit、HealthKit 这些框架为第三方应用的开发提供了便利,让第三方应用之间能够互相配合工作,降低用户的学习和迁移成本。出现新的软件或硬件功能时,也可以让第三方软件自动或简单地接入。所以我觉得不能简单地把 Apple 的生态描述为「封闭」,设计一个受控制但又能发展出繁荣生态的系统是非常困难的。
对于独立开发者来说,Apple 生态有着简单的学习路径、清晰的盈利模式,也正是因为如此,Apple 平台上有着大量高质量的独立软件,充分发挥比如 iPad、Apple Watch、Apple TV 这样的设备形态的独特优势。
硬件
Apple 在每个产品线上仅提供少量的 SKU,无论是不同产品线还是前后的两代产品,其设计都有着非常强的延续性。就我个人来说我更偏好这样有着清晰产品路线和规划的厂商,由厂商来对各种设计进行权衡,消费者只需做很少的选择。
因为 Apple 单个产品极大的出货量,Apple 是目前市场上为数不多能真正地按照自己的想法来决定产品的技术方向的公司 —— Apple 可以投入更多的资源去研发新技术,供应链的上下游也愿意配合 Apple 去将新技术落地。对于消费者来说,极大的出货量带来的好处则是更长的硬件支持时间、在遇到问题时更多的资料和配件,以及保值的二手价格。
实际上 Apple 也确实是在按照自己的标准在做硬件。你很难用其他厂商们都在竞争的屏幕刷新率、电池容量、相机像素数、内存容量去衡量 Apple 的产品,在很多配置参数上 Apple 确实并不占优,因为 Apple 的卖点始终都是包括软件功能在内的综合体验,硬件是为体验服务的,而不是为了与其他厂商竞争的。
前面聊了几个具体的方面,但如果说有一个最本质的原因导致了这所有的结果的话,我觉得就是「垂直整合」。所谓垂直整合就是指 Apple 一家公司同时完成硬件的设计和制造、操作系统和第一方应用的开发维护、提供 iCloud 这样的软件配套服务,最后还通过 App Store 控制着第三方软件生态。
这种垂直整合使得 Apple 能够对其产品在消费者手中的体验有着完全的控制,贯彻一致的产品设计逻辑,同时也对所有的体验负责。因此 Apple 并不急于使用新的技术去与其他厂商竞争,而是可以以自己的节奏进行打磨,推出系统性的解决方案(例如 Mac 到 ARM 的转型、未来的 visionOS)。
所以说 iPhone 的对手并不是 Android,而是每一个 Android 设备厂商;Mac 的对手也不是 Windows,而是每一个 Windows 设备厂商,而整个 Apple 在个人计算设备领域则完全没有相同体量的对手。
]]>
https://jysperm.me/2023/08/why-i-use-apple-devices/2023-08-09T17:00:00.000Z
在最近几年,我发现自己渐渐买齐了差不多所有的 Apple 设备,我使用 MacBook Pro 在写这篇文章、工作时使用 Mac mini、手机是 iPhone、手上戴着 Apple Watch、使用 AirPods 听播客、在床上用 iPad mini 看视频,蛋黄同样也]]>
为什么我选择 Apple 设备2023-12-06T12:33:18.000Z王子亭jysperm@gmail.com
2022 年疫情防控愈演愈烈,我们从三月开始经历了两个多月足不出户的严格封控。上海的封城可以说是非常严格,在一开始的半个月中物资供应受到了不小的影响,无法买到自己想要的食物,而除此之外的非生活必需品,更是直到六月解封才恢复正常。就在这样荒诞、焦虑和对未来的不确定的情绪中,我们浑浑噩噩地度过了这两个月。
这一年工作上面也发生了很多变化,很多一起工作多年的同事离开了我们。在外部环境好的时候大家当然都很开心,但当大公司面临压力时,这种压力自上而下传导时就会走样,好不容易建立的文化也会很快地被破坏掉。总的来说这一年的工作让我觉得不是很有成就感,花费了很多时间在难以对自己、公司或社会产生价值的事情上。在接下来的一年中,我希望自己能将之前仍有维护价值的 side project 捡起来,同时在开始新的项目时能够快速试错,用上我这么多年积累的工程经验,看看能否在几年内实现我理想中的自由职业。
今年我购买了我的第一台可更换镜头的相机 EOS M6 Mark II 和几支镜头,也拍摄了很多照片。此前我的照片一直是放在 iCloud 上的,编辑、整理、同步的体验非常好,但随着照片接近 200G 的容量上限,我花了一些时间去 寻找基于 NAS 的管理方案。但这些方案和 Photos 的差距实在是太大,再加上 iCloud 发布了 Shared Photo Library 和 Advanced Data Protection,最后我还是选择了升到 2T 继续用,NAS 仅作为备份使用。在近几年我开始越来越喜欢拍照,除了每张照片都是一个创作的过程中之外,整个照片库也是一个有关数字化的回忆的作品,所以我一直很重视照片库的管理,也是为什么只有 Photos 能够达到我的需求。
此外今年还购买了我的第一个全面屏手机 iPhone 13 mini 和 Steam Deck,也遇到了 Persona 5 这样相见恨晚的游戏,算是这沉重的一年中的一点色彩。
如何进行技术面试(面试官视角)2023-12-06T12:33:18.000Z王子亭jysperm@gmail.com
最近公司的很多同事都换上了搭载 M1 Pro 或 M1 Max 的新款 MacBook Pro,虽然日常使用的软件如 Chrome、Visual Studio Code 和 Slack 都已经适配得很好了,但面对 Docker 却犯了难。
众所周知,Docker 用到了 Linux 的两项特性:namespaces 和 cgroups 来提供隔离与资源限制,因此无论如何在 macOS 上我们都必须通过一个虚拟机来使用 Docker。
在 2021 年 4 月时,Docker for Mac(Docker Desktop)发布了 对 Apple Silicon 的实验性支持,它会使用 QEMU 运行一个 ARM 架构的 Linux 虚拟机,默认运行 ARM 架构的镜像,但也支持运行 x86 的镜像。
QEMU 是一个开源的虚拟机(Virtualizer)和仿真器(Emulator),所谓仿真器是说 QEMU 可以在没有来自硬件或操作系统的虚拟化支持的情况下,去模拟运行一台计算机,包括模拟与宿主机不同的 CPU 架构,例如在 Apple Silicon 上模拟 x86 架构的计算机。而在有硬件虚拟化支持的情况下,QEMU 也可以使用宿主机的 CPU 来直接运行,减少模拟运行的性能开销,例如使用 macOS 提供的 Hypervisor.Framework。
Docker for Mac 其实就是分别用到了 QEMU 的这两种能力来在 ARM 虚拟机上运行 x86 镜像,和在 Mac 上运行 ARM 虚拟机。
Docker for Mac 确实很好,除了解决新架构带来的问题之外它还对文件系统和网络进行了映射,容器可以像运行在本机上一样访问文件系统或暴露网络端口到本机,几乎感觉不到虚拟机的存在。但 LeanCloud 加入 TapTap 之后已经不是小公司了,按照 Docker Desktop 在 2021 年 8 月推出的 新版价格方案,我们每个人需要支付至少 $5 每月的订阅费用。倒不是我们不愿意付这个钱,只是我想要找一找开源的方案。
之前在 Intel Mac 上,我们会用 Vagrant 或 minikube 来创建虚拟机,它们底层会使用 VirtualBox 或 HyperKit 来完成实际的虚拟化。但 VirtualBox 和 HyperKit 都没有支持 Apple Silicon 的计划。实际上目前开源的虚拟化方案中只有 QEMU 对 Apple Silicon 有比较好的支持,QEMU 本身只提供命令行的接口,例如 Docker for Mac 调用 QEMU 时的命令行参数是这样:
~ ❯ limactl start docker.yaml? Creating an instance "docker" Proceed with the default configurationINFO[0005] Attempting to download the image from "https://cloud-images.ubuntu.com/focal/current/focal-server-cloudimg-arm64.img"INFO[0005] Using cache "/Users/ziting/Library/Caches/lima/download/by-url-sha256/ae20df823d41d1dd300f8866889804ab25fb8689c1a68da6b13dd60a8c5c9e35/data"INFO[0006] [hostagent] Starting QEMU (hint: to watch the boot progress, see "/Users/ziting/.lima/docker/serial.log")INFO[0006] SSH Local Port: 55942INFO[0006] [hostagent] Waiting for the essential requirement 1 of 5: "ssh"INFO[0039] [hostagent] Waiting for the essential requirement 2 of 5: "user session is ready for ssh"INFO[0039] [hostagent] Waiting for the essential requirement 3 of 5: "sshfs binary to be installed"INFO[0048] [hostagent] Waiting for the essential requirement 4 of 5: "/etc/fuse.conf to contain \"user_allow_other\""INFO[0051] [hostagent] Waiting for the essential requirement 5 of 5: "the guest agent to be running"INFO[0051] [hostagent] Mounting "/Users/ziting"INFO[0051] [hostagent] Mounting "/tmp/lima"INFO[0052] [hostagent] Forwarding "/run/lima-guestagent.sock" (guest) to "/Users/ziting/.lima/docker/ga.sock" (host)INFO[0092] [hostagent] Waiting for the optional requirement 1 of 1: "user probe 1/1"INFO[0154] [hostagent] Forwarding TCP from [::]:2376 to 127.0.0.1:2376INFO[0304] [hostagent] Forwarding TCP from [::]:8443 to 127.0.0.1:8443INFO[0332] [hostagent] Waiting for the final requirement 1 of 1: "boot scripts must have finished"INFO[0351] READY. Run `limactl shell docker` to open the shell.INFO[0351] To run `docker` on the host (assumes docker-cli is installed):INFO[0351] $ export DOCKER_HOST=tcp://127.0.0.1:2376INFO[0351] To run `kubectl` on the host (assumes kubernetes-cli is installed):INFO[0351] $ mkdir -p .kube && limactl cp minikube:.kube/config .kube/config
我还发现了另外一个基于 Lima 的封装 —— Colima,默认提供 rootful 的 dockerd 和 Kubernetes,但 Colima 并没有对外暴露 Lima 强大的自定义能力,因此我们没有使用,但对于没那么多要求的开发者来说,也是一个更易用的选择。
在默认的情况下,Lima 中的 Docker 在 Apple Silicon 上只能运行 ARM 架构的镜像,但就像前面提到的那样,我们可以使用 QEMU 的模拟运行的能力来运行其他架构(如 x86)的容器。qemu-user-static 是一个进程级别的模拟器,可以像一个解释器一样运行其他架构的可执行文件,我们可以利用 Linux 的一项 Binfmt_misc(中文版)的特性让 Linux 遇到特定架构的可执行文件时自动调用 qemu-user-static,这种能力同样适用于容器中的可执行文件。
社区中也有 qus 这样的项目,对这些能力进行了封装,只需执行一行 docker run --rm --privileged aptman/qus -s -- -p x86_64 就可以让你的 ARM 虚拟机魔法般地支持运行 x86 的镜像。
使用 qus 运行 x86 镜像的进程树如上,所有进程(包括创建出的子进程)都自动通过 QEMU 模拟运行。
回到题目中的问题,因为 Docker 依赖于 Linux 内核的特性,所以在 Mac 上必须通过虚拟机来运行;Apple Silicon 作为新的架构,虚拟机的选择比较受限,因为有些镜像并不提供 ARM 架构的镜像,所以有时还有模拟运行 x86 镜像的需求;Docker Desktop 作为商业产品,有足够的精力来去解决这些「脏活累活」,但它在这个时间点选择不再允许所有人免费使用;开源社区中新的项目都希望去 Docker 化,用 containerd 取代 dockerd,但这又带来了使用习惯的变化并且可能与线上环境不一致。因为这些原因,目前在 Apple Silicon 上安装 Docker 还是需要花一些时间去了解背景知识的,但好在依然有这些优秀的开源项目可供选择。
可以说 JavaScript 的生态来自于用户态类库的充分竞争,Deno 则在 Runtime API 之外提供了 Standard Library(类似 golang.org/x)、提供了全套的开发工具链(fmt、test、doc、lint、bundle),在试图提供开箱即用的使用体验的同时,也削弱了第三方生态。
选择这一款是因为从测评来看 Air 和 Pro 的性能差别并不显著,也不想为了 Touch Bar 和屏幕亮度支付额外 2000 元的价格,不如把这个钱加到内存上。
说到内存,新的 Mac 使用了「统一内存架构(UMA)」,可以消除 CPU 和显卡等专用计算单元之间的内存拷贝,既提高了速度,又减少了内存使用。一些朋友表示 8G 的内存对于不开虚拟机的中度使用也非常够用,但相信硬件的提升很快就会被软件消化,如果你希望新的 Mac 有一个比较长的使用周期,还是建议升到 16G 内存。对于新的 Mac 来说最高也只能选配 16G 内存,据说是因为总线 IO 的瓶颈,只有 2 个雷电接口也是这个原因。
拿到 MacBook Air 开始,最亮眼的还是发热和续航的表现,我偶尔会把 MacBook 放在腿上使用,之前的 Intel MacBook 十几分钟就会觉得烫,而 M1 Mac 则在日常使用时几乎感觉不到温度,在 CPU 跑满的情况下温热,只有 CPU 和 GPU 同时跑满才会有烫的感觉。相应地,M1 的续航表现也非常亮眼,后面的性能测试中会有详细的说明。
然后把它和我们家其他的 Mac 对比一下跑分,果然是用最低的价格提供了最高的分数:
Mac
Air (M1)
Pro (2020)
Pro (2017)
mini (2018)
CPU
M1
I5-1038NG7
I5-7360U
I7-8700B
GPU
7-Core
Iris Plus
Iris Plus 640
Intel UHD 630
Memory
16G
16G
8G
16G
Geekbench SC
1678
1136
852
1117
Geekbench MC
7225
4237
2020
5621
Geekbench Metal
19138
8498
4930
3776
Price
¥9499
¥14499
¥11888
¥11909
数据来自 everymac.com 和 geekbench.com
其中 MacBook Pro 2020 是我 2020 年初时购买的最后一代 Intel MacBook,使用第十代 i5,倒是没什么问题,只是目前来看就买得实在太亏了;MacBook Pro 2017 是蛋黄一直在用,最近她开始学习 Swift 就一直在吐槽电脑实在太慢了,同时电池也进入了待维护状态;Mac mini 2018 是我目前工作用的电脑,当时虽然选了最高配的 i7 CPU,但没考虑到 Intel UHD 630 的性能实在太差了,即使我只是接了一块 4k 屏,系统的界面响应就已经非常卡顿了,现在 GPU 成为了整台电脑的瓶颈。
ARM 生态
应该说这次从 x86 到 ARM 的切换比我想象中的要顺利,苹果的第一方应用和 masOS 独占的应用都第一时间进行了适配,其他没有适配的应用则可以用 Rosetta 2 来运行。Rosetta 2 用起来是完全无感的,系统会自动将 x86 的应用以转译的方式来运行,无论是图形界面应用还是命令行的 binary 文件。性能上的差别对于大部分应用来说也并不明显,很多时候感觉不到自己是否使用了 Rosetta 2。
M1 芯片之前对我来说最大的变数在于对 Docker 的支持,但就在前几天 Docker for Mac 也发布了 针对 M1 芯片的测试版本。测试版中默认会运行一个 ARM 架构的 Linux 虚拟机,默认运行 linux/arm64 架构的镜像(说起来在 M1 之前 linux/arm64 大概主要是被用在树莓派上吧);对于没有提供 linux/arm64 架构的镜像则会自动使用 QEMU 来运行 x64_64 的镜像,性能就比较差了。
macOS 吸引我的一大理由就是 Homebrew —— 可能是桌面开发环境中最好用的包管理器。在 M1 上 Homebrew 目前 推荐大家使用 Rosetta 2 来运行,所安装的包也都是需要 Rosetta 2 转译运行的 x86 版本,即使这个包已经提供了 ARM 版本。
当然你可以选择在另外一个路径 安装 ARM 版的 Homebrew 来安装 ARM 版的包,但目前这种方式缺少官方指引、需要自己尝试一个包的 ARM 版是否可以工作、需要从源码编译。目前大多数无法工作的包是受限于上游依赖的发布周期(如支持 darwin/arm64 的 Go 1.16 要等到 2021 年二月才会发布),对于不涉及特定架构、或已经在其他平台提供有 ARM 版本的包,届时只需重新编译就可以提供 ARM 版本。
M1 的 Mac 可以直接安装 iOS 应用这一点我倒不是很在意,一方面是很多国内的毒瘤应用第一时间就从 Mac 商店下架,不允许安装。另一方面 iOS 基于触屏的交互逻辑本来就不适合 Mac,我也不觉得 Mac 之后会加入触屏的支持。
性能测试
以极低的功耗实现高于之前 MacBook 的性能是这次 M1 Mac 的亮点,在我购买之前实际上就已经看了很多视频自媒体的测评,在他们的测试中 M1 Mac 在使用 Final Cut Pro X 进行视频剪辑和导出有着碾压级的性能表现。
但显然这并不能代表 M1 在所有工作负载下的表现,因此我根据我日常的工作负载设计了 7 组共 15 项测试,主要将搭载 M1 的 MacBook Air 和我目前在使用的最后一代 Intel MacBook Pro (2020, i5 10th) 进行对比,以下数据均以后者为基准。
16G 的内存也非常够用,即使另外一个用户运行了 XCode、Final Cut Pro X 或大量标签页的 Chrome,也不会有任何感觉。倒是 256G 的存储空间对于两个用户同时使用有些不够,不过这样的状态应该不会持续太久,后面我也会入手一台 M1 的 Mac。
对 Mac 的展望
Rosetta 2 为什么会有这么好的性能呢?之前 Surface 等 x86 模拟器性能不佳的一个原因是 x86 与 ARM 在一个有关内存顺序的机制上有着不同的行为,在 ARM 上模拟这一行为会导致很大的性能损失。而苹果选择直接 在 M1 芯片中实现了一套 x86 的内存机制,大大加速了 Rosetta 2 的性能。据说苹果同样在芯片层面对 JavaScript 和 Swfit 中一些特定场景进行了优化,还有大量的专用计算芯片来加速编视频编解码、密码学计算等特定的任务。
对于苹果来说切换到 ARM 最重要的是提升了其垂直整合的能力、自主控制 Mac 产品线的更新周期。因为苹果对于操作系统的控制力和对应用生态的号召力,可以最大限度地发挥出自主设计的 ARM 芯片的效果。Windows 阵营当然可以切换到 ARM,会享受到前面提到的一些好处,毕竟苹果已经证明了这条路是可行的。但因为软硬件不是同一家公司控制、Windows 对应用生态的号召力弱,微软又不敢破釜沉舟地投入到 ARM 上,因此短期内可能 Windows 阵营还很难实现。
前面提到 Interface 实际上是一组属性或一组约束的集合,说到集合,当然就可以进行交集、并集之类的运算。例如 type C = A & B 表示 C 需要同时满足类型 A 和类型 B 的约束,可以简单地实现类型的组合;而 type C = A | B 则表示 C 只需满足 A 和 B 任一类型的约束,可以实现联合类型(Union Type)。
在 TypeScript 中你可以将类型设置为 any 来绕过几乎所有检查,或者用 as 来强制「转换」类型,当然就像前面提到的那样,这里转换的仅仅是 TypeScript 在编译阶段的类型标注,并不会改变运行时的类型。虽然 TypeScript 设计上要去支持 JavaScript 的所有范式,但难免有一些极端的用例无法覆盖到,这时如何使用 any 就非常考验开发者的经验了。
type Todo struct { orm.ObjectMeta Name orm.String `orm:"name"` Priority orm.Number `orm:"priority"`}todo := Todo{ Name: orm.NewString("test"), Priority: orm.NewNumber(1),}err = orm.Save(&todo)todo.Name.Set("test")todo.Priority.Incr(1)err = orm.Save(&todo)fmt.Println(todo.Name.Get(), todo.Priority.Get())
这个方案可以做到不以字符串的形式传递字段名(可以得到编译期的类型检查),可以追踪对每个字段进行的修改(包括 Incr 等运算)。我将 Set 添加到了基本类型的封装类型上,将 Save 作为了一个全局方法,避开了 Golang 对于继承的限制。带来的问题则是用户需要通过我们的封装方法(Get)来访问字段的值;同时今后设计嵌套对象时也需要更大的工作量。
TypeScript 有着一个先进的类型系统,这种先进并非是学术意义上的先进,而是工程意义上的先进。它几乎可以为所有 JavaScript 中常见的范式添加静态约束,得益于强大的类型推导,在大部分情况下并不需要自己添加类型标注,但却能在编译期提前发现错误、配合 Language Server 得到准确的代码补全和类型提示信息,完全没有前面提到的 Golang 中的那种束缚感。
同时我也不得不接受 Atom 的市场已经几乎完全被 VS Code 取代的现实,切换到了对 TypeScript 支持更好的 VS Code。现在想想 Atom 失败的原因一方面是在 CoffeeScript 已经表现出没落的时候选择了 CoffeeScript;另一方面是希望依靠社区的力量,但又缺乏对社区的引导。例如对于插件的 GUI 改动引导不够导致界面卡顿,对于代码补全、调试等常见需求没能建立统一的标准等等。
旷野之息选择了一种类似赛璐珞的风格来渲染 3D 模型,带来了一种非常特殊的、类似水彩画的视觉风格。旷野之息在掌机模式下是 720p 30 帧,TV 模式下是 960p 30 帧,只能说是一个中规中矩的数据,不如同时期游戏在我的 Windows PC 上的效果。实际游玩过程中在极少数光影比较复杂的雨林场景会有明显的掉帧,其他的时候都非常流畅。
在此之外,游戏并没有限制你在什么样的阶段可以去挑战什么样的敌人。你在游戏的过程中可以感受到更大程度上是因为你的技术的提升(或者说对游戏机制的了解),你才能够逐步地去挑战更强大的敌人。除了一开始的初始台地之外,游戏也没有限制你在什么样的阶段可以去到地图的哪个区域,在非常早的阶段,你就获得了去到地图上任意一点、甚至跳过剧情直接挑战最终 Boss 的能力。
值得一提的时候我高中有那么一年多在玩 EVE 这个游戏,其实说起来 EVE 在飞船的操纵上已经十分简化了,游戏背景中的先进科技也绕开了现实中的燃料和光速等限制。但在 EVE 中驾驶飞船给了我对于宇宙的一种直观的认识 —— 星球是如此地大、星球之间的距离是如此地远,其余的空间都是一片虚无,如果没有一个坐标的话,你几乎不可能和别人相遇。
蛋黄同样对太空探索很感兴趣,近两年我们也看了不少相关的纪录片,我们经常互相拉着对方讲新了解到的关于太空探索有趣的事情:蛋黄讲得比较多的是历史,而我会更关注技术。我们关注最多的具体项目还是阿波罗计划了,毕竟是人类首次登上另外一颗星球,直到目前依然保持着人类所到达的最远的地方的记录。在做了更多了解之后,我发现其实有非常多的美国公司(尤其是飞机制造商)都参与了阿波罗计划,负责具体的火箭和飞船制造,而 NASA 主要负责的是设计和组织,整个项目也可以算是人类历史上最宏大的工程之一了。
提到太空探索的爱好者,就必须要提 Kerbal Space Program(坎巴拉太空计划)这款游戏,基本上在知乎这样的社区只要涉及航天或火箭相关的话题,评论区就一定有人刷坎巴拉的梗。在我入手这个游戏后便很快沉迷无法自发,在游戏中我可以亲手实现之前的文字或视频中见到过无数次的技术:发射入轨、霍曼转移、交会对接、反推着陆、引力弹弓。也对比冲、Δv 之类的数值有了更深刻的认识,之后再看纪录片的时候就能脑补出其中提到的各种操作了。后面我应该会专门写一篇文章来介绍坎巴拉太空计划这个游戏。
那么为什么我对于太空探索如此着迷呢?首先我还是视它为一种兴趣,是因为去了解这些知识会让我感到高兴和满足,而不是我要用这些知识做一件什么事情。相比于其他的学科,例如数学、物理甚至是计算机,最新的研究成果几乎都是我无法理解的,并不适合作为消遣和兴趣;而美国人登陆了月球、火星发现了液态水、木卫四可能存在生命这些就要好理解得多。这大概是因为作为太空探索的主力 —— NASA 的大部分资金都来自于财政拨款,这要求它必须以一种普通人能够理解的方式,向美国的纳税人解释他们的工作,以得到更多人的支持、得到更多的拨款。
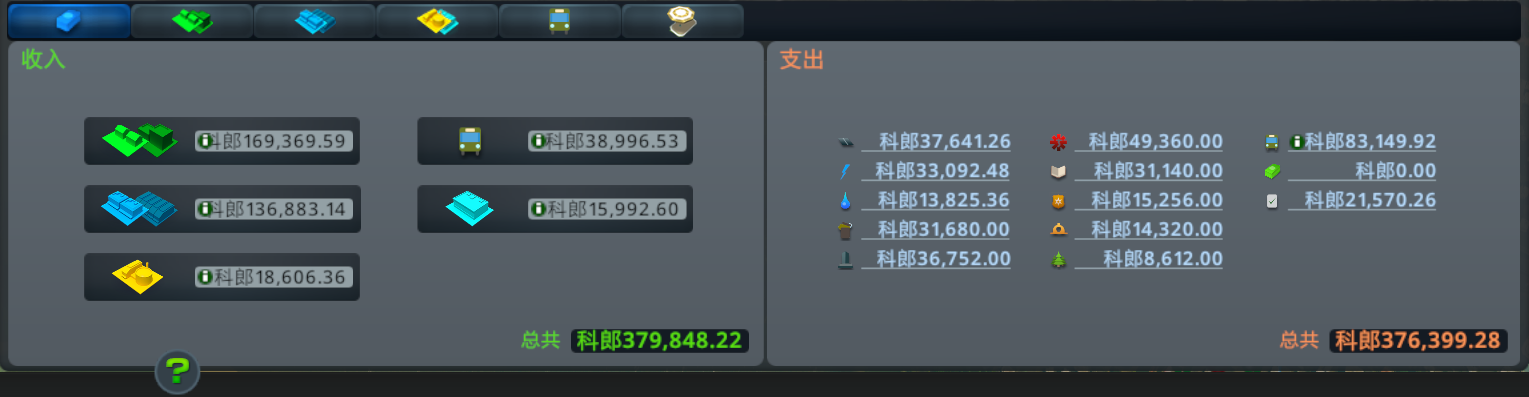
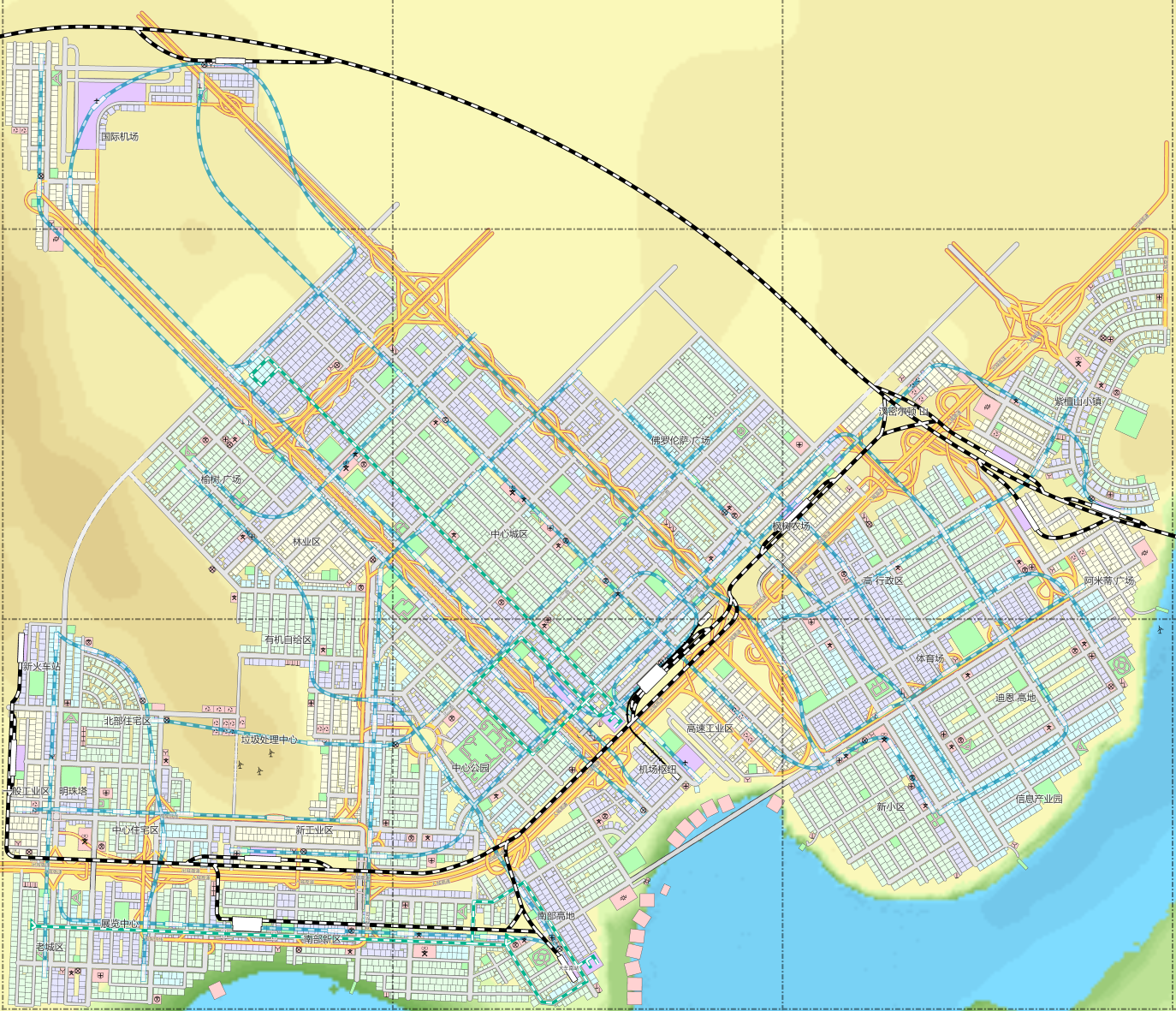
天际线的经营要素并不是很强,只要前期不作死 —— 不规划远超实际需要的基础设施,就不太可能出现破产的情况,从中后期开始主要的重心还是在交通上面。当然不同的人在玩这个游戏时会有不同的目标,我的目标是在不使用 Mod 的情况下、在默认的游戏规则下,建造一个看上去符合「常理」、运转起来也符合「常理」的城市。
于是我开始使用 verror 这个库,它最主要的功能是帮助你创建一个「异常链」,你可以在每个层级来向异常上补充路径信息(会被反映到 err.message 例如一个来自底层的错误信息可能是 request failed: failed to stat "/junk": No such file or directory 这样)。这个异常链信息也会和其他元信息一起以结构化的方式存储在错误对象上,这个库也提供了一些工具函数来获取这些结构化信息。我尝试使用 verror 来管理所有的异常,报告带有详细的、每一层级信息的异常。同时我也会向错误对象上附加一些元信息用来指示如何响应客户端、是否需要发到 Sentry、是否可以重试等。
除了异常,我也开始尝试使用 bunyan 打印结构化的日志,并存储到 Elasticsearch。通过 Kibana 的 Web UI 可以很简单地对日志进行筛选和查询,在排查问题时找到相关的那部分日志。对于一个既有的系统来说,调整异常和日志可以说是一个非常庞杂的工作,在调整的过程中也我也在不断地修正自己的实践,今年一整年我都在做这样的尝试。