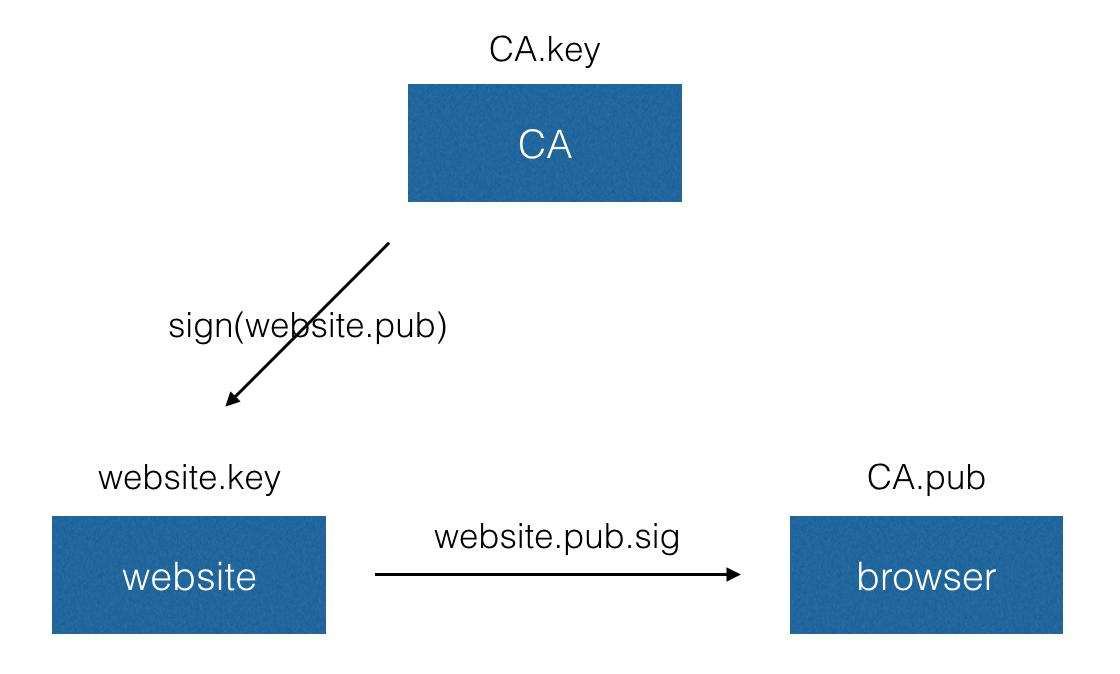
在 X.509 中有一个被称为「证书颁发机构(CA)」的权威的第三方,CA 的数量较为有限,资格变化也并不频繁,所有浏览器(browser)都内置了 CA 的公钥。而网站方(website)在生成了自己的公钥后,需要先找 CA 对自己的公钥进行签名然后才能使用。当浏览器访问一个新的网站时,网站方需要提供经过 CA 签名的公钥,浏览器使用内置的 CA 公钥来验证签名,确保收到的网站的公钥没有被篡改过。
X.509 实际上就是要求大家信任一个权威的第三方并将它们的公钥内置在客户端中,这并不是一个完美的方案,因为在这个体系中 CA 有着非常大的权力,一旦 CA 不按照规则签发证书,那么客户端是无法察觉这种攻击行为的。
GPG
GPG 是 PGP(Pretty Good Privacy)的一个 GPL 实现,也是目前使用最广泛的实现。
「信任一个权威的第三方」对于一些去中心化爱好者是无法接受的:首先我们凭什么去信任这个第三方,其次在 CA 申领证书通常也是需要付费的。那么有没有可能去除这个权威的第三方,而允许大家互相进行认证呢?如何确认一个公钥就是属于这个人的呢?这就是我们接下来要介绍的 GPG 的信任模型:
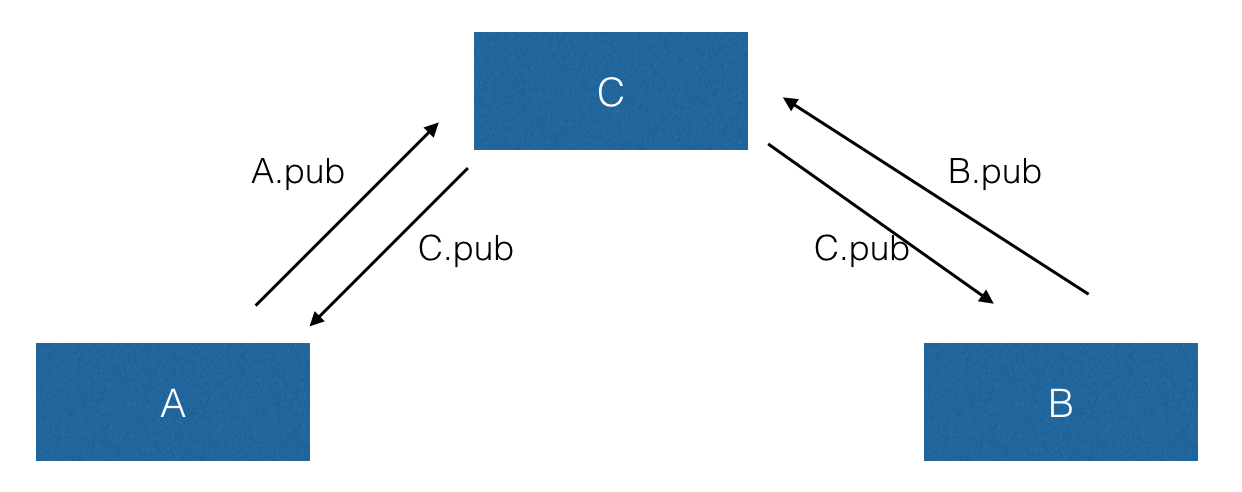
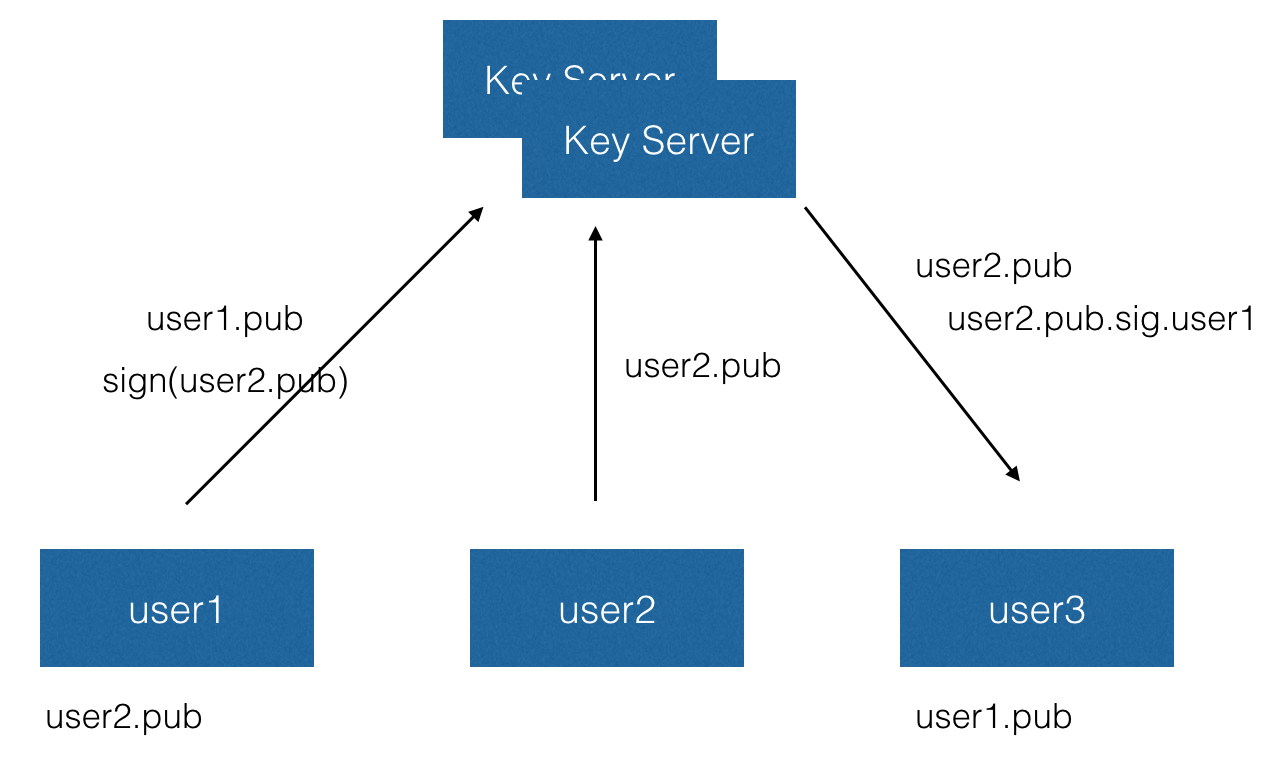
在 GPG 的信任模型中,用户互相之间对公钥进行认证(通过用自己的私钥进行签名的方式),例如 Alice 和 Bob 是很好的朋友,要么 Alice 就会用自己私钥给 Bob 的公钥签名,然后将这个签名通过 Key Server 广播给其他人。Key Server 仅仅用来交换公钥和签名,因为签名本身是可校验的,所以 Key Server 并没有任何特权。
当另外一个 Alice 的朋友看到 Bob 的公钥,并且发现 Alice 给 Bob 的公钥签过名,那么就可以认为他的朋友 Alice 已经检查过 Bob 的公钥了,如果看到更多朋友给 Bob 签过名,那么就几乎可以认定 Bob 的身份是真实的。
我还可以使用根公钥签署一个类似于「我授权 1D795875 为我的子密钥,可以代替我进行签名等操作」的消息来添加额外的子密钥,例如上面的三个 sub 就是三个不同功能的子密钥。就像这样,其实对于 GPG 帐号的管理操作都是通过用私钥签名消息来实现的。
还可以列出与我有关的签名:
1 2 3 4 5 6 7 8
~> gpg --list-sigs jysperm pub 4096R/E466CF1E 2014-11-23 [expires: 2017-05-17] uid Wang Ziting <jysperm@gmail.com> sig C07CFB96 2016-05-04 paomian <qtang@leancloud.rocks> sig 3 7CDC82A7 2015-05-11 Yeechan Lu <wz.bluesnow@gmail.com> sig 3 E466CF1E 2016-05-17 Wang Ziting <jysperm@gmail.com> sig E411E711 2016-06-02 keybase.io/librazy <librazy@keybase.io> sig B0B002B8 2016-07-13 dennis (Dennis Zhuang) <killme2008@gmail.com>
~> pass git pull --rebase remote: Counting objects: 11, done. remote: Total 11 (delta 1), reused 1 (delta 1), pack-reused 10 Unpacking objects: 100% (11/11), done. From github.com:jysperm/passwords 5026f34..e94a70f master -> origin/master First, rewinding head to replay your work on top of it... Fast-forwarded master to e94a70f8b42af5e1c13dd69246b156bbcb24a94c.
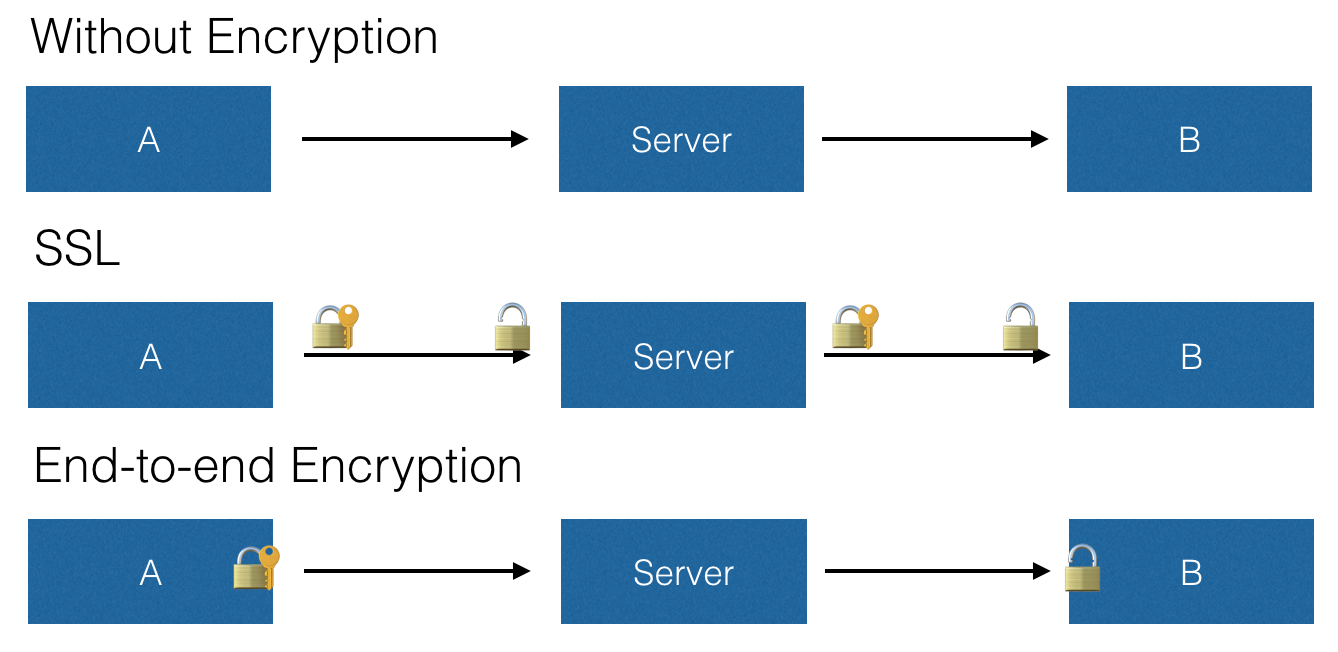
我们再来转向这篇文章的第二个话题「端到端加密」,下图中分别展示了在无加密、SSL 加密和端到端加密的场景下,从 A 到 B、中间经过服务器的一次通讯的过程:
在没有加密的情况下,消息从 A 到服务器、再到 B 的全程都没有加密。这也意味着数据经过的链路上的任何一个节点(例如运营商的路由器)都可以查看和修改消息的内容,这种情况下的通讯安全是完全没有保证的。
在经过 SSL 加密的情况下,A 和 B 会分别在收发消息前通过 CA 签署的证书去认证服务器的身份,并协商一个用于加密数据的密钥。在从 A 到服务器,或从服务器到 B 的过程中,SSL 会保证数据不被窃听和篡改,但消息在服务器上则是以未加密的形态存在的,服务器可以查看和修改消息的内容,进行一些内容上的审查。
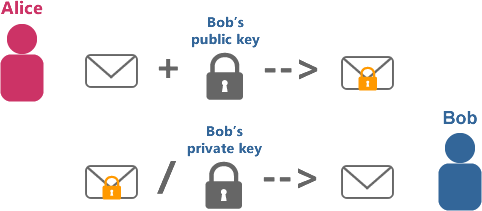
在端到端加密的情况下,消息在从 A 发出之前,就会利用我们前面介绍过的公钥加密技术,使用 B 的公钥进行加密,中间以加密的形式经过服务器和其他路由节点,直到 B 收到消息后,才使用自己的私钥进行解密。这种情况下的服务器并不能查看和修改消息,仅仅作为一个渠道来转发消息。
我们当然可以简单地使用 GPG 加密我们在第三方即时通讯软件上的聊天内容,就像下面这样:
但实际上例如 Tox、Line、WhatsApp、iMessage 等 IM 软件,都是默认提供了端到端加密的特性的,我们下面以 iMessage 为例去介绍一个 IM 软件是如何完成端到端加密通讯的。
~> ssss-split -t 3 -n 5 Generating shares using a (3,5) scheme with dynamic security level. Enter the secret, at most 128 ASCII characters: my secret root password Using a 184 bit security level. 1-1c41ef496eccfbeba439714085df8437236298da8dd824 2-fbc74a03a50e14ab406c225afb5f45c40ae11976d2b665 3-fa1c3a9c6df8af0779c36de6c33f6e36e989d0e0b91309 4-468de7d6eb36674c9cf008c8e8fc8c566537ad6301eb9e 5-4756974923c0dce0a55f4774d09ca7a4865f64f56a4ee0
~> ssss-combine -t 3 Enter 3 shares separated by newlines: Share [1/3]: 3-fa1c3a9c6df8af0779c36de6c33f6e36e989d0e0b91309 Share [2/3]: 5-4756974923c0dce0a55f4774d09ca7a4865f64f56a4ee0 Share [3/3]: 2-fbc74a03a50e14ab406c225afb5f45c40ae11976d2b665 Resulting secret: my secret root password
当一个矿工 A 挖到一个新的块的时候,他会将这个 Block 广播出去,其他人一旦收到了这个消息,就会立刻基于这个新的块开始工作。而其他人在「A 挖到新的块」和「收到 A 广播的消息」之间这段时间之间的计算实际上是被浪费掉了的,而中心化矿池中的其他矿工则不会有这个问题,因为他们可以更快地得到新产生的块的信息,立刻在新的块的基础上开始工作。
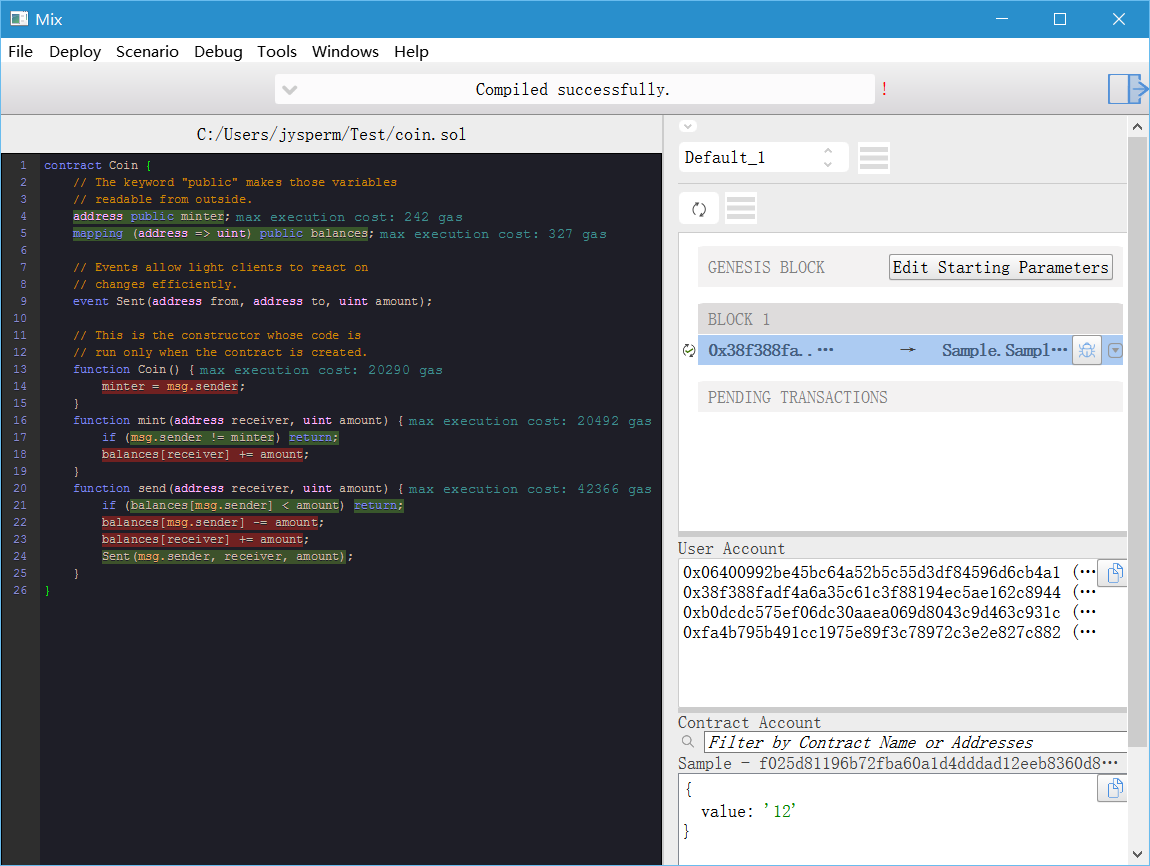
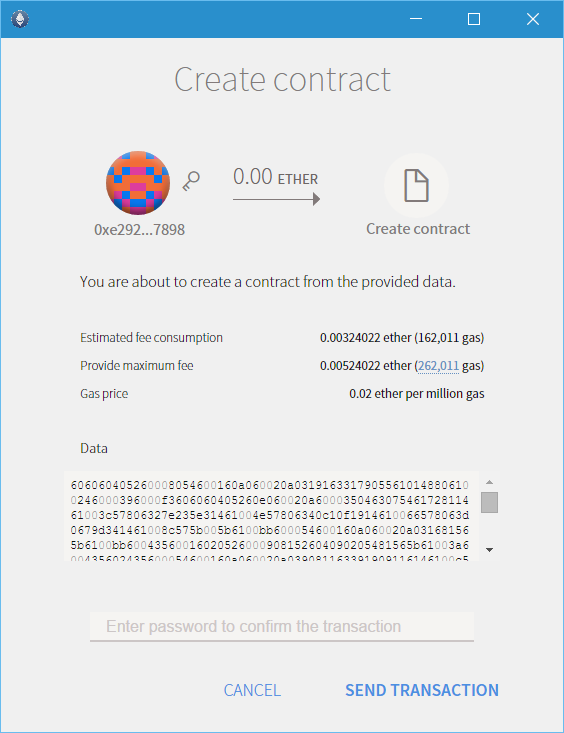
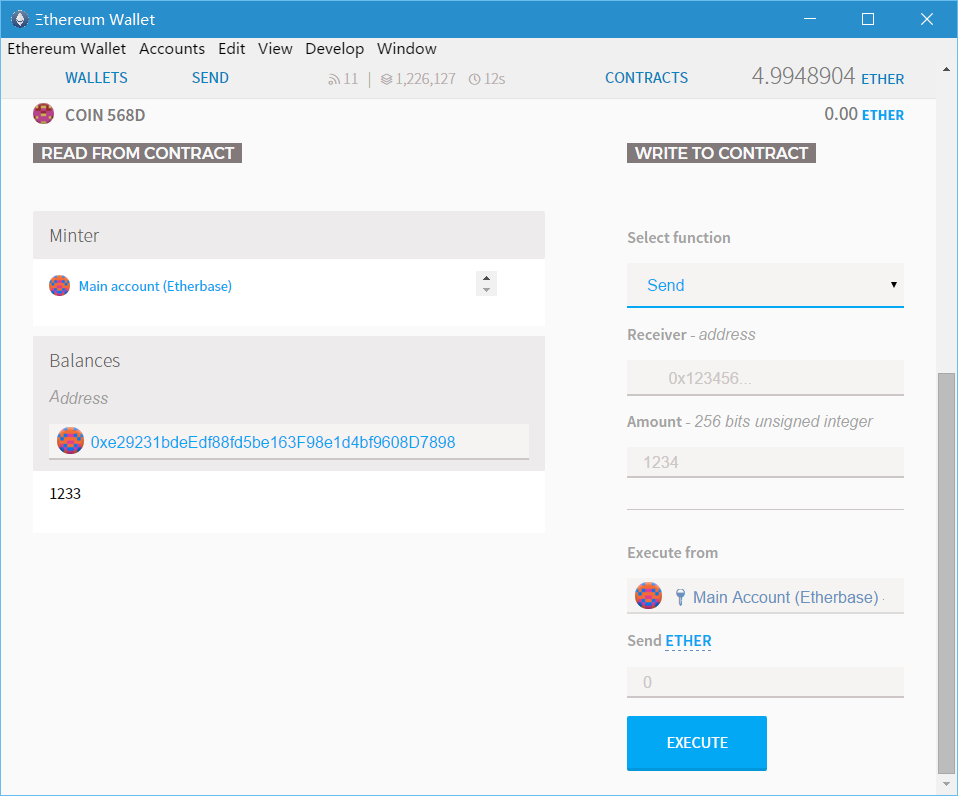
contract Coin { // The keyword "public" makes those variables // readable from outside. address public minter; mapping (address => uint) public balances;
// Events allow light clients to react on // changes efficiently. event Sent(address from, address to, uint amount);
// This is the constructor whose code is // run only when the contract is created. functionCoin() { minter = msg.sender; } functionmint(address receiver, uint amount) { if (msg.sender != minter) return; balances[receiver] += amount; } functionsend(address receiver, uint amount) { if (balances[msg.sender] < amount) return; balances[msg.sender] -= amount; balances[receiver] += amount; Sent(msg.sender, receiver, amount); } }
// for every three new participants we can // pay out to an earlier participant if (idx != 0 && idx % 3 == 0) { // payout is triple, minus 10 % fee uint amount = 3 ether; participants[payoutIdx].etherAddress.send(amount); payoutIdx += 1; } }
提高计算成本即通过将算法设计得更为复杂,增加更多次计算,来提高对单个信息进行散列的时间。对于正常单次散列来讲,即使增加十倍的计算时间,仍然是可以接受的。但当攻击者进行暴力破解时,同样需要原来十倍的计算时间,这个成本对攻击者来说可能无法接受。除此之外,还可以改造算法,使其只能运行于 CPU 上,无法使用显卡或专用芯片进行计算,以提高暴力破解的计算成本。 但似乎这种方式并没有被业界接受,SHA 系列函数中的新成员均减少而不是提高了计算成本。
在攻击者不知道 salt 的情况下,有两种选择。 一是将 hash2(x) 改为 hash2(x, salt), 这种情况适用攻击者知道 salt 的长度或范围的情况,因为这个函数有两个参数,因此破解成本与 x 或 salt 的长度呈指数函数,只要 salt 足够长,那么可以认为攻击者即使暴力破解也无能为力。 二是将第二个 hash 的输入视为一个散列值,换言之就是进行两次爆破,这种方式的计算成本相比于前一种会更高,因为暴力破解的成本同原文长度也是呈指数关系的。
接下来,那么如何生成 salt 呢?是否有必要为每条数据(还是前面的例子,每个用户)使用单独的 salt 呢。通过前面的讨论我们看到,要保证单向性,对 salt 进行保密十分必要。如果你能够保证 salt 的绝对安全的话,那么是否使用单独的 salt 其实无关紧要。不要担心使用相同的 salt 会让攻击者找到某种规律而计算出 salt(当然前提是 salt 足够长), 因为 MD5, SHA 系列函数保证了单向性,攻击者无法从散列值推测出原文的任何信息。
至于 salt 的取值,没有什么特别的要求,基于保密的考虑,通常要使用随机生成的字符串,然后就是足够长(大约等于散列值的长度).
但我们认为仍有必要为每条数据使用单独的 salt, 这是基于下面两点考虑。 一是虽然暴力破解需要惊人的计算力,但是如果只需破解一个散列值,就可以获知所有数据的 salt, 这个破解也是值得的,也许攻击者就能够提供这么多的计算力也说不定,虽然如果你使用足够长的 salt 的话,这种可能性极小。 二是也许你不能保证 salt 的绝对安全,当你的 salt 泄漏后,每条数据使用不同的 salt 将会为攻击者制造最后一道障碍。
如果你所有的数据都使用同样的 salt, 那么攻击者在拿到数据后,只需进行一次暴力破解,即可破解出所有的数据(如果都命中了的话), 但如果你为每条数据使用不同的 salt, 那么攻击者将不得不为每条数据单独运行一次暴力破解,因为每条数据相当于在使用不同的散列函数,因为 salt 是不同的。
综上,我们认为网站的用户系统使用下面的散列即可保证安全性:
hash(hash(passwd) + salt)
其中 salt 是随机生成的,长度等于散列值长度的字符串。hash 可以是 MD5 或 SHA 系列函数。